
 العربية
العربية
 English
English
📄 Automated PDF Data Extraction
منذ 6 أشهر
عرض العمل

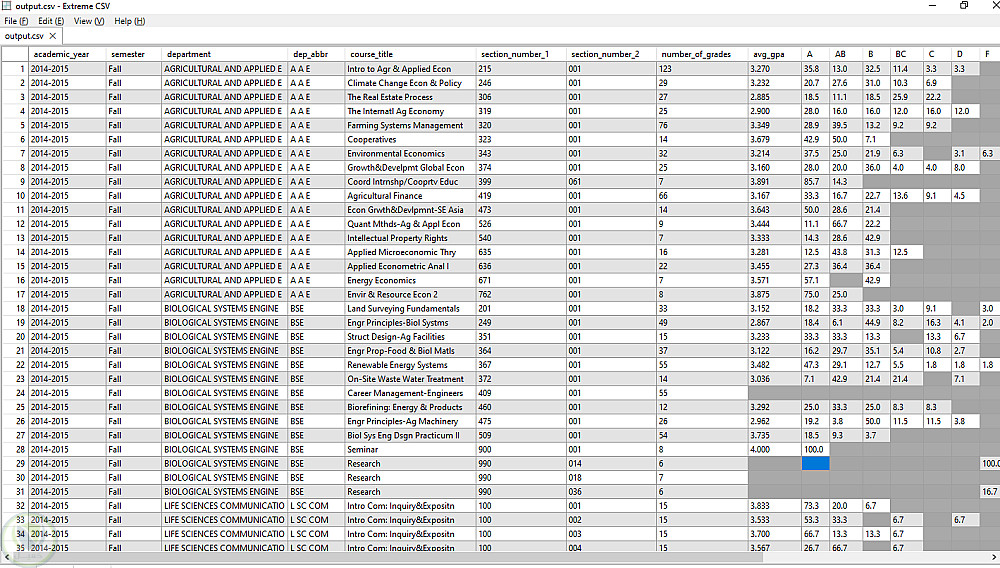
الوصف
📄 Automated PDF Data Extraction
عميل احتاج استخراج بيانات من 20 ملف PDF (8,000+ صفحة) كانت عملية شبه مستحيلة يدويًا.
الحل: طورت سكربت بـ Python باستخدام pdfplumber + Regex لمعالجة النصوص، وصدّرت النتائج في CSV منظم.
النتائج:
معالجة 8,000+ صفحة في 15 دقيقة بدل أسابيع.
استخراج 50,000+ سجل بدقة ~95%.
وفرنا 98% من الوقت مع ملفات ضعيفة الجودة.
القيمة: بيانات نظيفة وجاهزة للتحليل، تقارير فورية، وحل مرن قابل لإعادة الاستخدام.
التفاصيل
| المشاهدات | 17 |
| المفضلة | 0 |
| القسم | برمجة, تطوير المواقع و التطبيقات - أنظمة إدارة المحتوى |
حساب المستخدم

بائع مستوي: جديد
Frontend Developer | React, Next.js, Three.js & GSAP Expert
| اخر ظهور: منذ 4 أشهر
تفتكر العميل ممكن ينسى موقعك بعد ما يخرج منه؟ أنا هنا عشان أساعدك تبني تجربة كاملة تفضل عالقة في باله، مش مجرد موقع وخلاص. مهمتي تحويل واجهتك الرقمية ....
وظفني