العربية
العربية
 English
English
تصنيف البيانات باستخدام خوارزميات الـ Machine Learning

الوصف
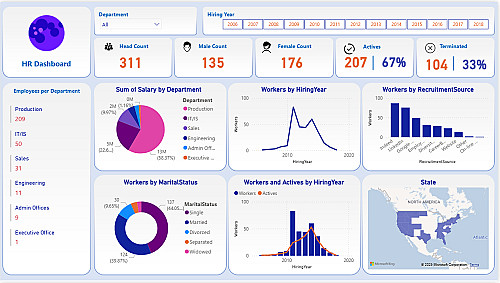
نقدم خدمة برمجية سريعة لتنفيذ مهمة واحدة محددة (Single-Task) في مجالات تعلم الآلة، مع التركيز على تصنيف البيانات (Classification) وتجميعها (Clustering). نهدف إلى تحويل بياناتك الخام إلى نماذج ذكية ورسوم بيانية توضيحية احترافية تساعدك في اتخاذ قرارات دقيقة.
تنبيه هام: هذه الخدمة تغطي خياراً واحداً فقط من القائمة أدناه مقابل كل طلب (Order)، وذلك لضمان أعلى جودة في التنفيذ خلال 24-48 ساعة.
خيارات الخدمة (اختر مهمة واحدة فقط):
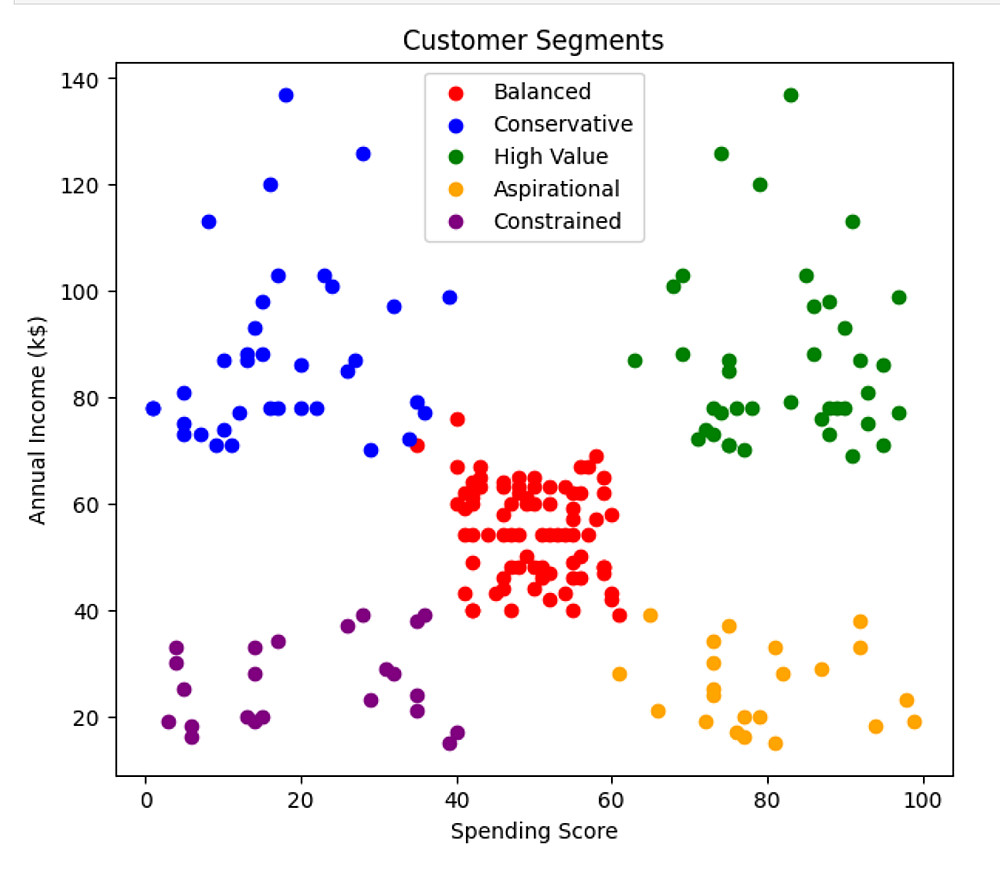
Customer Segmentation: تنفيذ خوارزمية K-Means لتجميع البيانات وإنشاء Scatter Plot ملون يوضح المجموعات (Segments).
Binary/Multi-class Classification: بناء نموذج لتصنيف البيانات إلى فئتين أو أكثر باستخدام خوارزميات مثل SVM أو Random Forest.
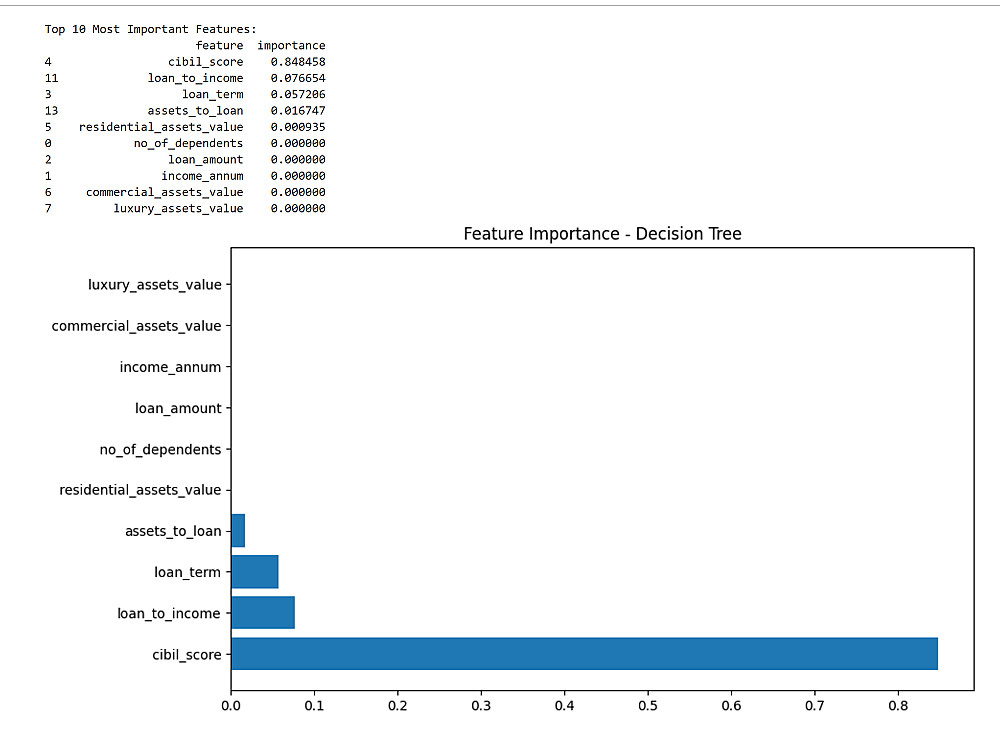
Feature Importance Analysis: تحليل البيانات لتحديد المتغيرات الأكثر تأثيراً في النموذج وعرضها عبر Bar Chart احترافي.
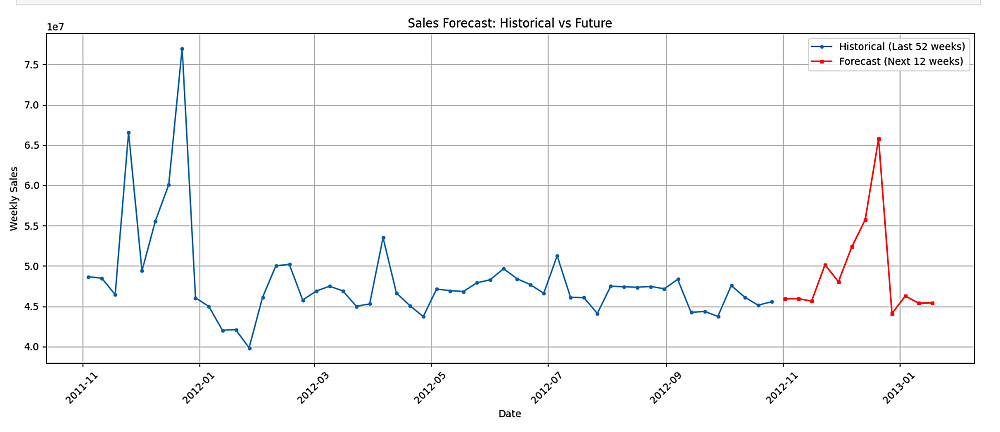
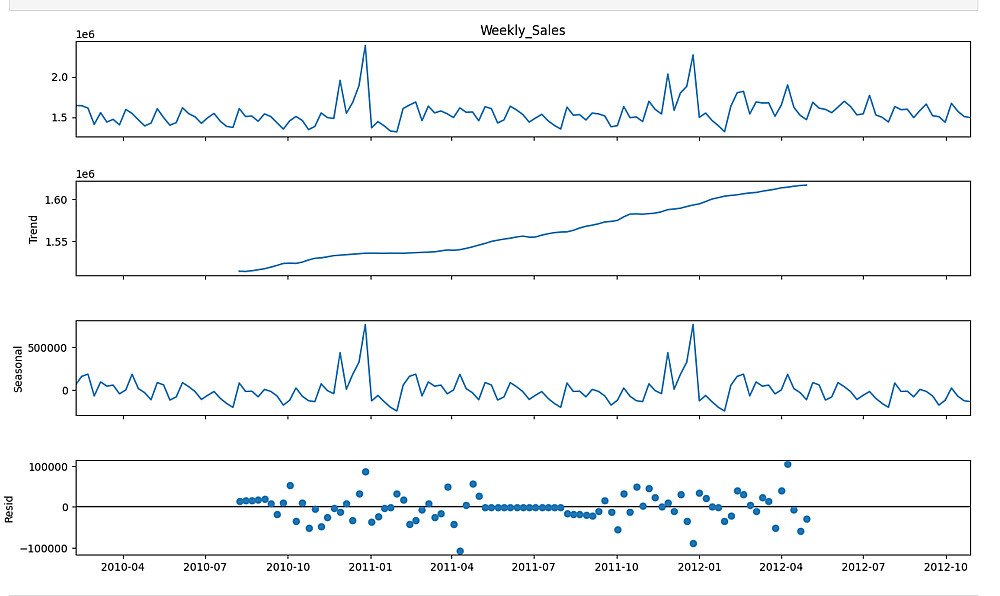
Data Visualization Task: تحويل بياناتك إلى رسوم بيانية متقدمة (مثل Time Series Decomposition) لفهم الأنماط والموسمية.
المخرجات (Deliverables):
Source Code: ملف Jupyter Notebook (.ipynb) شامل ومنظم برمجياً.
Model Graphics: الرسوم البيانية الناتجة (مثل الـ Clusters أو الـ Feature Importance) بدقة عالية.
Evaluation Metrics: تقرير موجز يوضح دقة النموذج (Accuracy) أو جودة التجميع (Silhouette Score)
البائع

بائع مستوي: جديد
Machine Learning Engineer
| اخر ظهور: منذ 3 أيام
أعمل على سد الفجوة بين البيانات المعقدة والبرمجيات الوظيفية. وسواء كنت بحاجة إلى نموذج تعلّم آلي تنبئي (Predictive ML Model)، أو نص برمي آلي عالي السرعة، أ ....
تواصل معيمعلومات

خدمات أخري للبائع

الخدمات المقترحه