العربية
العربية
 English
English
تصنيف النصوص والأخبار العربية بالذكاء الاصطناعي (NLP & Deep Learning)

الوصف
هل تواجه صعوبة في تصنيف الكم الهائل من النصوص أو الأخبار العربية يدوياً؟ أقدم لك حلاً تقنياً متقدماً باستخدام أحدث نماذج الذكاء الاصطناعي ومعالجة اللغات الطبيعية (NLP) لتصنيف النصوص العربية بدقة عالية.
ما الذي ستحصل عليه في هذه الخدمة؟
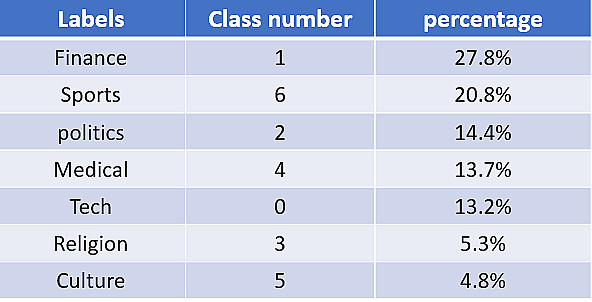
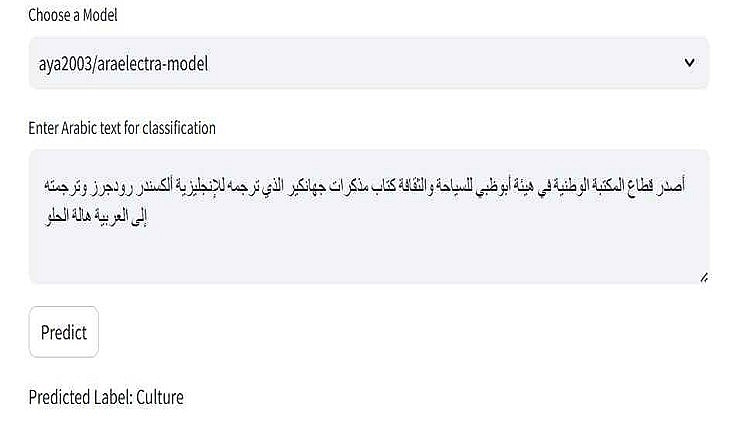
1) تصنيف النصوص والأخبار: تصنيف آلي دقيق للمقالات والنصوص العربية إلى فئات محددة (مثل: سياسة، رياضة، اقتصاد، ثقافة، وغيرها).
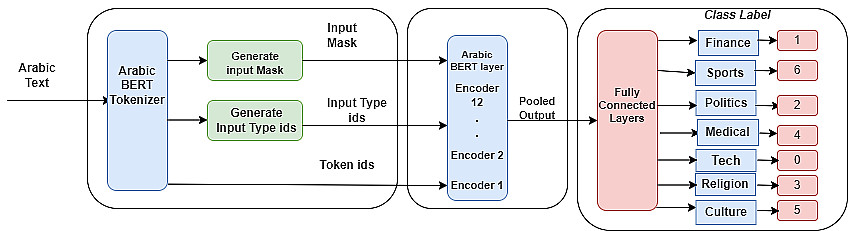
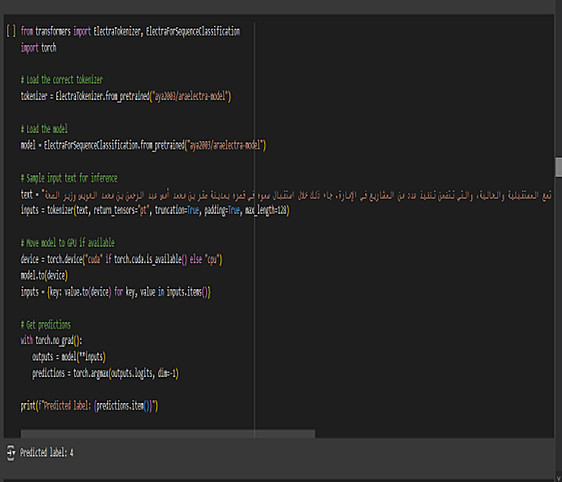
2) استخدام تقنيات حديثة: توظيف أقوى النماذج مثل MarBert, BI-LSTM, AraElectra لضمان أفضل النتائج.
3) معالجة البيانات الضخمة: القدرة على التعامل مع مجموعات بيانات كبيرة جداً (مثل SANAD dataset).
4) تنقية النصوص (Preprocessing): تنظيف النصوص العربية من الرموز التعبيرية، الروابط، علامات التشكيل، والكلمات الزائدة لضمان دقة التحليل.
5) دقة عالية: الوصول لنسب دقة مرتفعة تتجاوز 90% في بعض النماذج المستخدمة (مثل AraBert و BI-GRU)
ما الذي ستستلمه
1) كود برمجي: ملف Colab (Python) او VS Code موثق ومنظم يشرح خطوات العمل.
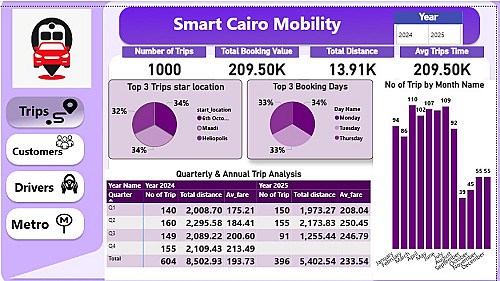
2) ملف توثيقي PDF Document: رسم بياني يوضح دقة النموذج (Accuracy & Loss) وتوزيع الاحتمالات لكل تصنيف
3) نموذج ذكاء اصطناعي (Model): ملف النموذج المدرب جاهز للاستخدام
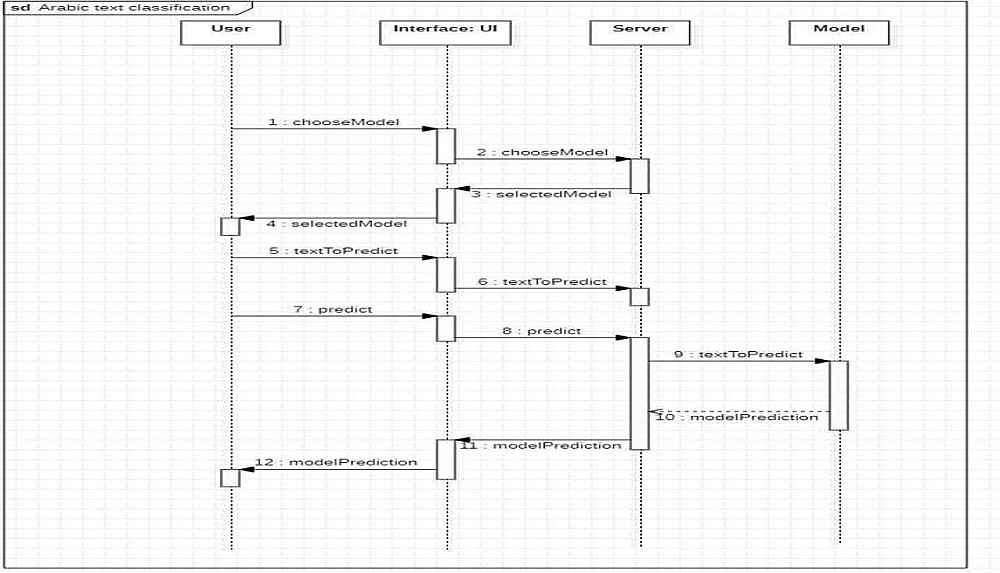
4) واجهة تطبيق (اختياري): تطبيق ويب بسيط (Streamlit) لرفع النصوص وتصنيفها برمجياً.
البائع

بائع مستوي: جديد
AI & Data Scientist
| اخر ظهور: منذ 8 ساعات
خريجة ذكاء اصطناعي متخصصة في تطبيقات أتمتة الذكاء الاصطناعي ونماذج اللغات الكبيرة (LLM). أمتلك معرفة تقنية في مسارات تحليل البيانات (Data Analytics) من خلا ....
تواصل معيمعلومات

خدمات أخري للبائع


الخدمات المقترحه