
 العربية
العربية
 English
English
نظام استخراج بيانات من مواقع الويب بتنسيقات متعددة مع قابلية للتخصيص بسهولة
منذ 9 أشهر
عرض العمل

الوصف
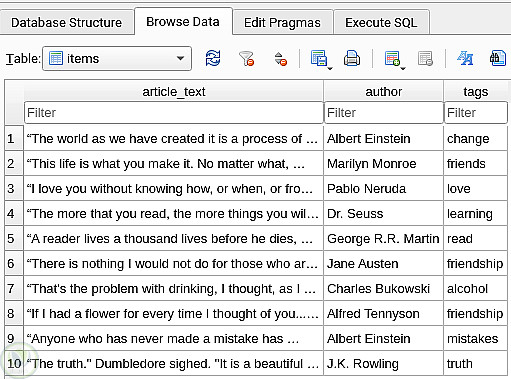
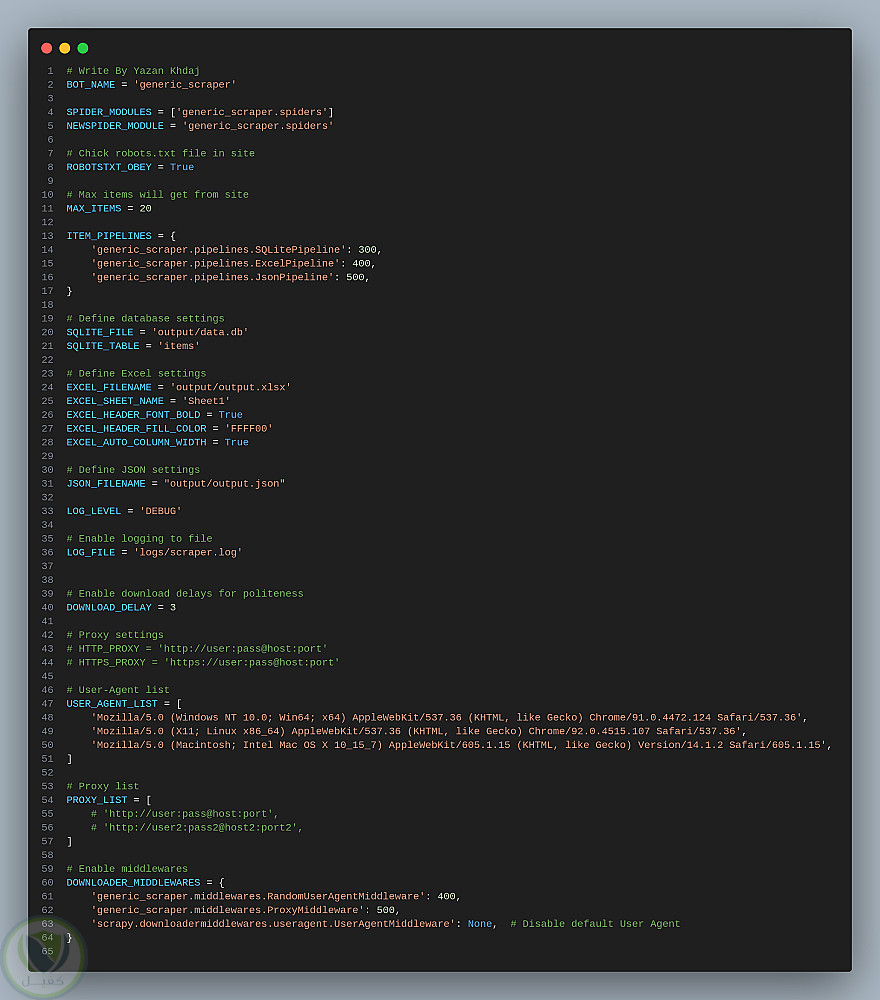
نظام متكامل لاستخراج بيانات الويب بكفاءة يتميز ببنية معيارية مرنة تسمح بتخصيص كامل لسلوك الاستخراج دون الحاجة لتعديل الكود الأساسي.
يعتمد النظام على:
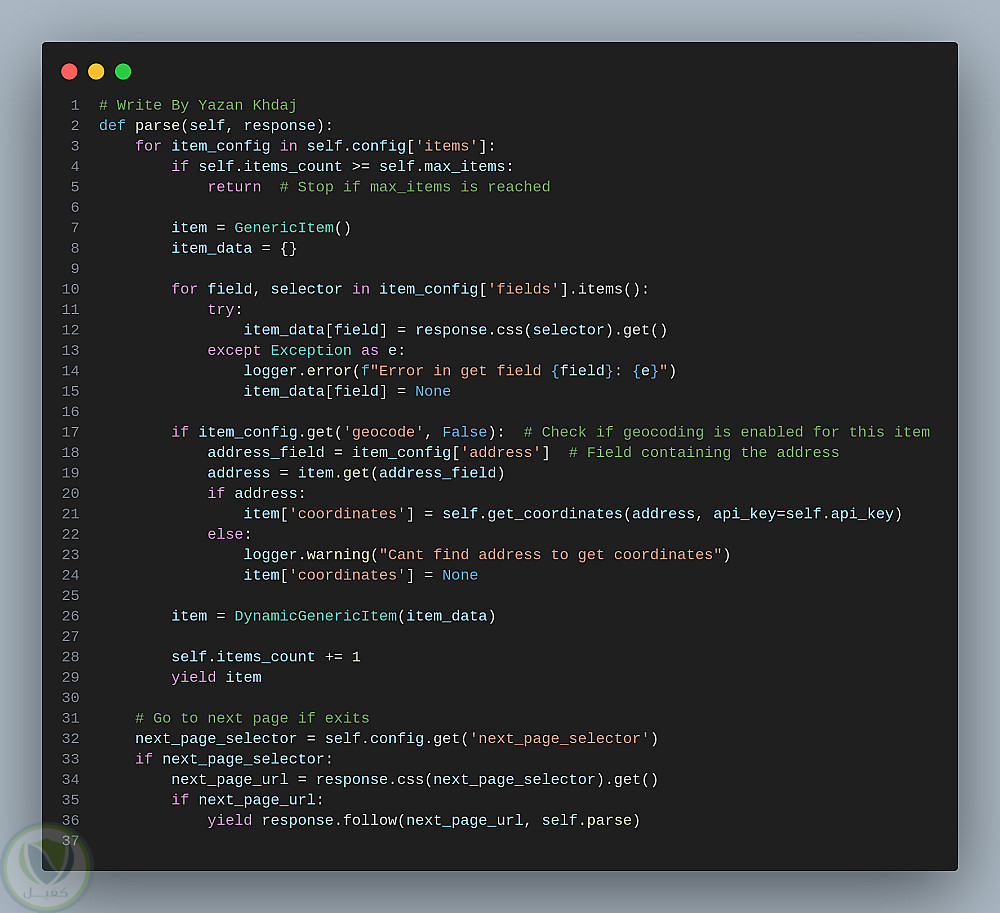
Scrapy Spider: محرك الاستخراج الرئيسي.
ملفات إعداد وتكوين:(settings.py و config.json) لتحديد الإعدادات العامة والمواقع المستهدفة، عناصر البيانات، وقواعد المعالجة.
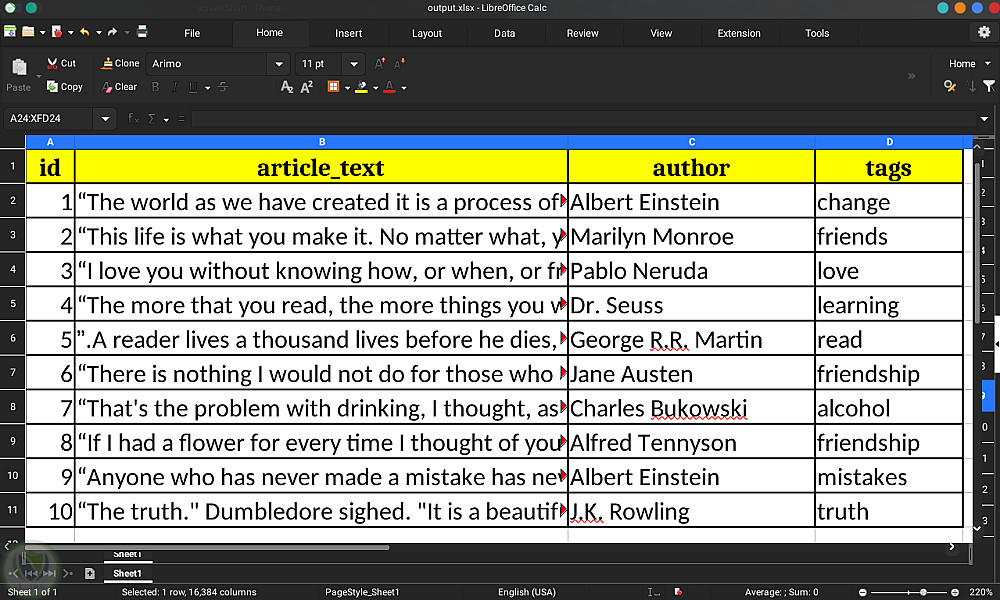
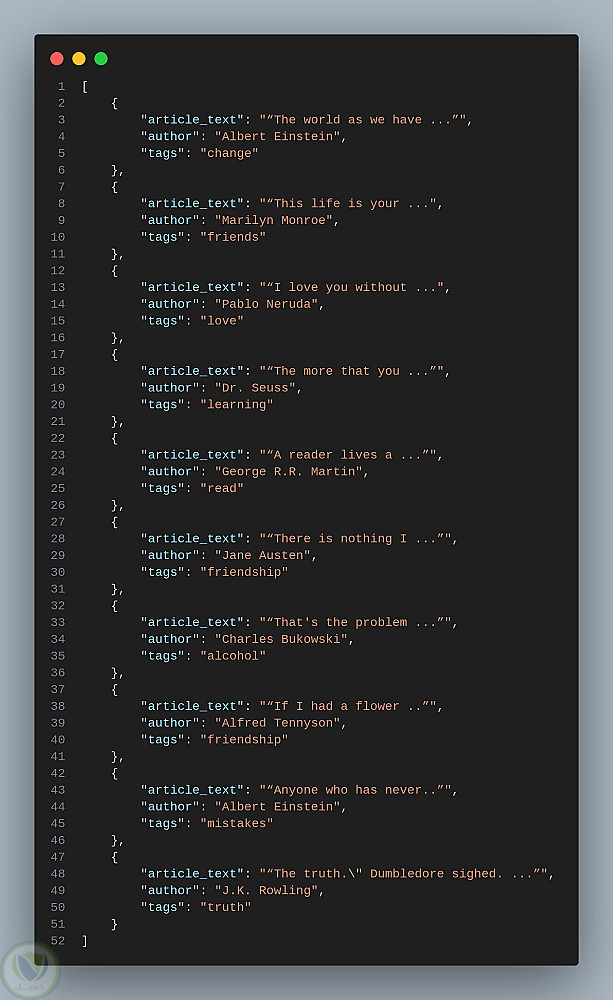
Data Pipeline: لتحويل البيانات وتخزينها بتنسيقات متنوعة (SQLite، JSON، Excel).
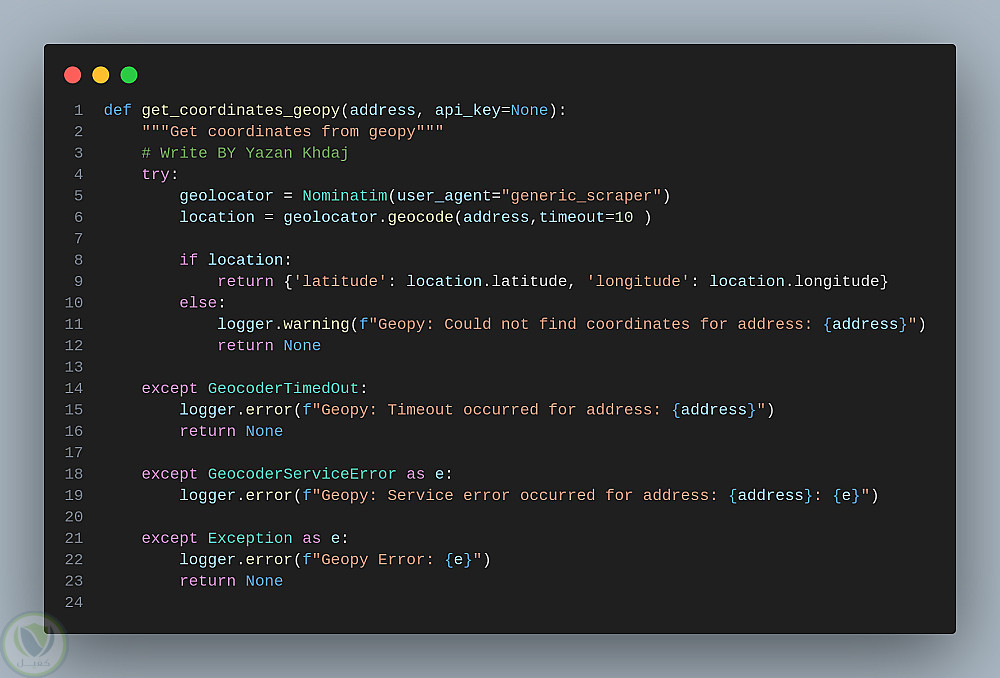
Geolocation Module: لاستخلاص خطوط الطول والعرض من العناوين باستخدام APIs خارجية.
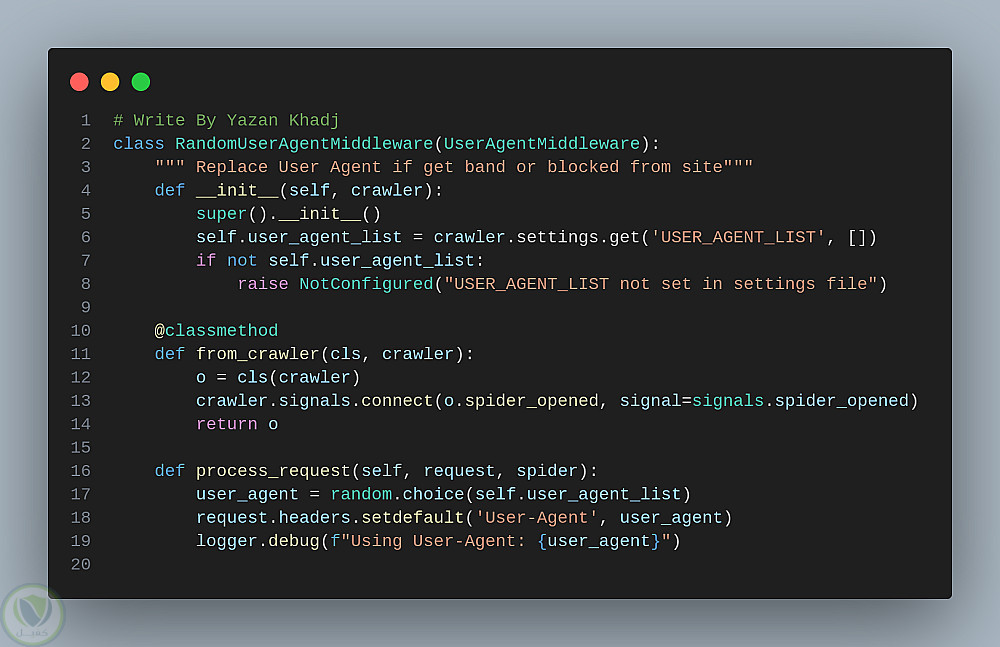
Middlewares: لإدارة الطلبات والاستجابات (تأخير، وكلاء، ملفات تعريف الارتباط).
آلية مكافحة الحظر: تتضمن تأخيرات عشوائية، تدوير User-Agent، وإدارة الوكلاء لتجنب الحظر.
الخصائص المميزة:
فصل التكوين عن الكود: منطق الاستخراج مُعرف في ملف JSON لتعديل السلوك بسهولة.
بنية معيارية: تصميم معياري يسهل إضافة مكونات جديدة لتوسيع الوظائف.
معالجة مرنة للبيانات: سلسلة عمليات لتنظيف وتنسيق البيانات المستخرجة.
التفاصيل
| المشاهدات | 34 |
| المفضلة | 1 |
| القسم | برمجة, تطوير المواقع و التطبيقات - مواقع الويب |
حساب المستخدم

بائع مستوي: جديد
System Administrator
| اخر ظهور: منذ 4 أشهر
مبرمج متخصص في تطوير البرمجيات وإدارة خوادم Linux. أعمل على تحسين الأداء والأمان، وتصميم بُنى تحتية مرنة، وتطوير التطبيقات باستخدام Python وسكربتات Shell.
وظفني